How the Centre for the Study of Existential Risk's Civ V mod should make us fear superintelligent AI
AI-mageddon


What do you reckon is the greatest threat to the future of humanity? Climate change? Nuclear war? A global epidemic? They’re all causes for concern, but it’s my belief that one of the greatest risks is actually posed by superintelligent AI.
You might need some convincing of that, which is why researchers at the University of Cambridge’s Centre for the Study of Existential Risk have made a mod for Civilisation V that introduces potentially apocalyptic AI. Ignore the pressing need for AI safety research, and it’s game over.
I tried it out last week, seeking to answer two questions. Does it accurately portray the risks involved with the development of a god-like being? And is it any fun?
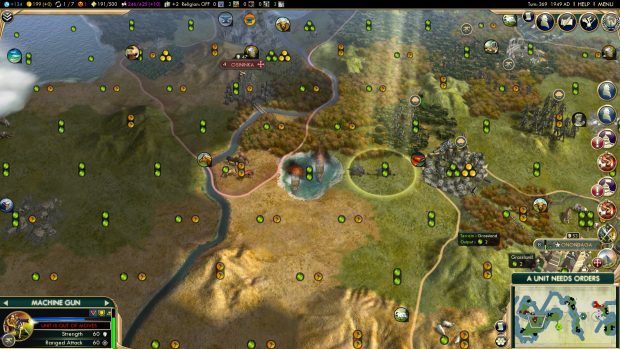
The mod revolves around replacing the normal science victory condition. Instead of launching a spaceship to Alpha Centauri, you have to accrue a certain number of AI research points. Certain buildings generate that research - but you can’t just build willy nilly. For every research centre that exists across the map, an AI risk counter will also tick up. If it reaches 800, everybody loses: all of humanity succumbs to an unconstrained superintelligence that warps the world to its twisted goal.
If that sounds like an unfeasible scenario to you, then you’re exactly the kind of person that the CSER is hoping will check out the mod. The idea is to not only alert people to the possibility that superintelligent AI could be a threat that needs addressing, but to illustrate how the Earth’s geopolitical situation might exacerbate that threat. For example, one of the new late game technologies is militarised AI: developing it would have given me a military edge, but significantly added to the risk counter.
That example also shows why I don’t think the mod quite succeeds as either education or entertainment. I’ll dig into the science communication side of things shortly, but for now I’ll just look at it as a game. The major problem is that all of the changes that come with the mods are late-game additions - and the late-game is by far the weakest part of Civ.

As with many 4X games, once you start pulling ahead in Civ you become something of an unstoppable train. I found that my level of technology so far exceeded that of my neighbours that the military AI didn’t tempt me in the slightest. For exactly the same reason, I didn’t feel any pressure to build an unsafe number of research centres - I could just wait until I could construct safety centres, which reduce the rate that the risk metre ticks up by.
In fairness, much of that comes down to the difficulty I was playing on. I’ve always found the regular ‘prince’ difficulty in Civ V to be a little too easy, while the next one up is far too hard. In an ideal Civ game where victory was only just within reach, the tension between giving myself an advantage and increasing the likelihood of global catastrophe would have been an interesting decision - a decision that may very well be made one day in the real world.
That’s an example of how the mod could have been accurate but in practice isn’t, but there are other aspects of it that ring true. One of those is how you reach the technology to research AI long before you reach the technology required to start making it safe, which is a key point often made by AI safety advocates. Also accurate is the way the civilisation that tops out their AI research first secures total victory: the race to build a superintelligence is a winner takes all scenario, unless that superintelligence turns out to be uncontrollable.
That’s all well and good, but those successes are undermined by its failures. The resounding issue here is how the mod tells you the exact point at which the AI will take over, when a large part of the real-life danger stems from our uncertainty as to when that will become a possibility. We don’t know how long it will take us to create the conditions for a safe superintelligent AI, which is the strongest argument I know for us to start doing what we can as early as possible.
Admittedly, investing in a game as long as Civ and having it suddenly end at an unknowable point doesn’t sound like it would be much fun. Nevertheless, it remains the case that telling you exactly what’s required to prevent a superintelligence based catastrophe inaccurately represents one of the most concerning elements of the threat. Changing the way the system works might not be the best idea, but I do think the mod should have found a way to acknowledge that inaccuracy.
I was also expecting that the mod would go to greater lengths to explain why that’s a threat worth taking seriously. There are some relevant quotes when you research the new technologies, but that’s pretty much it. Adding in an ‘AI adviser’ to replace the science one would have been ideal. It feels like a wasted opportunity to get the actual reasons to worry about AI in front of people - and I don’t want the same to be true of this article.
Yep, it’s time for a crash course in AI theory. It’ll be fun, promise!
First though, it’s worth noting that hundreds of papers (written by people better informed than me) have been written on the topics I’m going to whizz through in a few paragraphs, and some of them oppose arguments that I’m about to bring up. Nevertheless, there’s a growing number of intelligent people who consider long-term AI safety research as paramount to ensuring our continued existence as a species - so it’s worth hearing them out, eh?
Before we get to the potential dangers of a superintelligent AI, we need to clear up whether it's even possible. I’ll defer here to the argument that Sam Harris makes in this excellent TED talk. Here’s the gist: if we accept that intelligence is a matter of information processing, that humans will continue to improve the ability of machines to process information, and that humans are not near the summit of possible intelligence - then in lieu of an extinction event, it’s almost inevitable that we’ll develop some form of superintelligence.
We could spend forever digging into those assumptions, but let’s move on to the danger that such an intelligence might pose. The Future of Life institute manages to dispel a popular misconception and cut to the heart of the issue with one sentence: “the concern about advanced AI isn’t malevolence but competence”. AI isn’t going to ‘turn evil’ or 'rebel', but there are good reasons to believe that ensuring its goals are truly consistent with those of humanity will be fraught with pitfalls. This is the value-alignment problem, and it’s a biggy.
Nate Soares, the executive director of the Machine Intelligence Research Institute, has the best introduction to the alignment problem that I’ve come across. That article highlights how giving an AI a seemingly safe, simple task can go disastrously wrong. If you instruct an AI to fill a cauldron with water, for example, you might hope that it would simply pour in the water can call it a day. What you’d be forgetting is what Soares calls “the probabilistic context”:
“If the broom assigns a 99.9% probability to “the cauldron is full,” and it has extra resources lying around, then it will always try to find ways to use those resources to drive the probability even a little bit higher.”
This leads us to the director of The Future of Humanity Institute, Nick Bostrom, and his instrumental convergence thesis. It sounds more complicated than it is, honest. The argument goes that with almost any end-goal you give an AI, there are certain instrumental goals that it will also pursue in order to achieve that final goal.
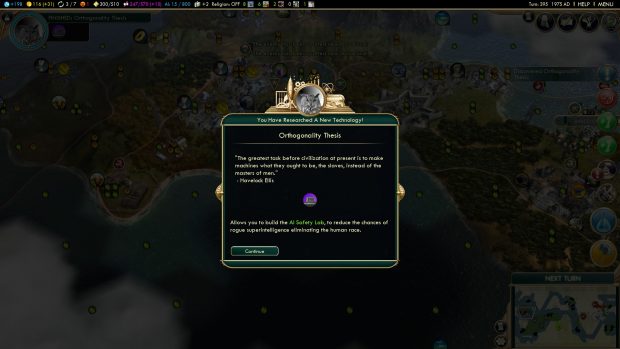
So with Soares's cauldron filler, one way for the AI to increase its certainty that the cauldron has been filled is to maximise its intelligence. How might it go about doing that? Maybe by turning every resource it can get its hands on into computer chips. Reckon that we’ll just be able to turn it off? Another instrumental goal suggested by Bostrom is self preservation, so it’s unlikely to be that easy (Soares goes into detail about problems with “suspend buttons”).
I’ve gone into so much detail because a) I think it’s both important and fascinating and b) Bostrom’s instrumental convergence lies at the crux of whether or not the mod is realistic in depicting doom as the default scenario. “Is the default outcome doom?” is actually the title of a chapter in Bostrom’s book on Superintelligence, and it’s a question that even he is reluctant to respond with a firm yes - though that is the answer his arguments build up to.
It needs to be acknowledged, though, that that position is far from being the scientific consensus. Mike Cook, the chap behind game-making AI Angelina, recently wrote a blog post in which he argues that the mod “feels less like a public awareness effort and more like a branding activity for the lab”. He raises a lot of good points, not the least of which is that the CSER stands to gain from exaggerating the threat and getting people talking - unless that exaggeration loses people’s trust in the long term.
Personally, I don't think the mod exaggerates the threat of smarter-than-human AI. If anything, the lack of an upfront explanation about why AI safety is something to take seriously could lead people to dismiss the issue. It’s a point that brings me back to how much the mod could have benefited from including that AI adviser, who could have communicated the key arguments at relevant points.
It was only after I'd finished my game that I realised the mod does include detailed Civlopedia entries for the new technologies and wonders. That means those key arguments are in the mod, but with nothing to draw your attention to the Civlopedia I fear most people will miss them just as I nearly did. I love the idea behind the mod, but I'm not convinced it succeeds as either something that's fun to play or as something to learn from. Most of my issues with it as a game are intractable, being more to do with Civ itself than the mod - but with the right tweaks, the mod could still be a powerful tool for highlighting and explaining the issues around AI safety.
If you want to read more about the mod, check out our interview with its creator.